中文字体压缩的那些事
实在是对页面上一成不变的中文字体腻烦了,于是我对自己说:管他什么 web 安全字体呢,我就想要养眼的阅读体验不可以吗?漂亮的中文字体那么多,为啥我非得从那几种丑丑的字体里面选择不可呢?
于是我就从免费字体仓库里面选了一款,打算放到博客上用,问题是,原始字体文件有好几兆,如果直接放到博客上面,那读者就不得不忍受长达几秒的加载时间,这样肯定不合适啊,于是我想到了字体压缩。
压缩成果
在开始废话之前,先上结果图表,省得浪费观众老爷的时间,下表列出了常见的免费字体在压缩前后的对比:
| 字体名称 | 完整大小 | 常用2000 简体字 | 常用3500 简体字 | 根据本博客动态生成 |
|---|---|---|---|---|
| 思源黑体 | 10.0M | 532K | 1.0M | 407K |
| 思源宋体 | 13.8M | 706K | 1.4M | 539K |
| 仓耳舒圆 | 3.7M | 952K | 1.9M | 721K |
| 仓耳渔阳 | 1.6M | 390K | 783K | 297K |
思源系列是最广泛使用的中文字体了,尤其是在 linux 上 , 不过我想没人会折腾思源字体吧?否则还不如用googlefonts api 何苦折腾什么压缩。这里列出来只是为了作为参照,我选择的字体是仓耳的免费商用系列。仓耳系列非常轻巧好看,我最中意的是仓耳今楷, 可惜这个字体只能个人免费使用,放到博客上很可能会惹来麻烦。最后我只能退而求其次选择了渔阳,这个字体比较接近今楷, 而且还是永久商用免费的,可以放心在博客上使用。
思源字体包含的汉字远比仓耳系列多,所以压缩率看起来比较高。一般的字体经过压缩都能达到20% 的压缩率。
注:
什么是字体压缩
原始的字体文件为什么大?那是因为里面内置了超大的汉字字符集,其中大部分汉字其实平时根本不会用到。字体压缩就是只从中选择用到的部分进行精简。就我来说,平时使用的汉字不到2000 个,而一般支持GBK 的字体里就有近7000 个汉字。
有哪些现成的压缩工具
现在开源社区已经有非常多的压缩工具供我们使用了,我了解到的有:
- font-spider: 非常流行的压缩方案,可以自动分析出页面使用的 webfont 进行压缩。使用的语言是 nodejs
- font-spider-plus: 字面意义上的增强版
- fontmin: 可以通过制定文本进行压缩,也是 nodejs
- fonttools: 定制性更强的压缩工具,使用的语言是 python
我的选择
几乎所有的中文博客推荐的都是 font-spider, 有少量提到了 fontmin, 还有很少一部分两三年前的博客提到了 fonttools.
不选择 font-spider 的理由
font-spider 虽然看上去超级自动化,但往往“自动化”就意味着“低容错”。比如我在尝试对 hugo 生成的 html 进行解析时,直接报错,提示我不存在 /css/font.min.css 之类的文件—— exm ?为什么会去根目录下找 css? 我在 public/css 下放的东西是干啥用的?
最后我也没能成功跑起来,而更令我恼火的是几乎所有提到 font-spider 的文章都是一个模子刻出来的一样,尽在说怎么怎么好用,就是没说该怎么用。感觉这些作者似乎都在说一套旁人听不懂的“暗语”,而我最讨厌的就是谜语人了。最后我猜想的是可能这个工具只适合用来解析 webpack 打包的前端工程吧, pass.
因为一个小问题遗憾放弃 fontmin
而 fontmin 的情况好些,可能是因为不像 font-spider 那么自动化,所以使用起来比较简单,在实践过程中我确实能够顺利跑起来(尽管还是浪费了大量的时间试图弄懂到底该怎么用),但最后还是遇到了一个 issue.
我比较讨厌 javascript 所以没有去翻源码,于是将目光放到了 fonttools.
拥抱 fonttools
文档丰富,功能齐全,更新勤快,最关键的是用 python 写的,安装过程令人舒适,不像基于 npm 的工具麻烦不断。就决定是你了。
fonttools 安装很简单,一行命令: pip install fonttools brotli --user
其中 brotli 是用来将 ttf 转换成 woff2 以进一步提升压缩率的,如果不想转换为 woff2 可以不用安装。
两种压缩方案
选择常用字进行压缩
这种方法最简单,直接选取常用汉字表进行压缩,不需要经常更新,如果有 CDN 的话可以选择这种方案。
下载上文给出的常用汉字表,或者自己写一份想要的汉字表保存为纯文本,然后在命令行输入:
pyftsubset <你的字体>.ttf --text=$(cat <所需的汉字表文件>) --no-hinting
这个命令会在当前目录上生成 <你的字体>.subset.ttf 文件,直接使用即可。
根据使用情况动态压缩字体
使用上面的方法会产生两个问题:
- 即便已经足够精简,但还是有些字根本用不到
- 而有的时候我们会用到的字,常用字表里面却没有
为啥那么多人推荐 font-spider? 就是因为它的核心功能:能自动获取页面上使用到的字符进行压缩。而 fontmin 和 fonttools 都没有这个功能。难道我要回过头去折腾 font-spider 然后说“真香”?
绝不。事实上我们可以通过一行代码“实现” font-spider, 是时候祭出万能的 ripgrep 了:
rg -e '[\u4e00-\u9fa5]' -oN --no-filename|sort|uniq|tr -d '\n'
命令解释:
rg即ripgrep, 字面意义上 grep 终结者。能以超快的速度查找多个文件中的内容。- 默认会对当前目录下所有文件(除了二进制和隐藏文件)进行检索
-e '[\u4e00-\u9fa5]'指定正则表达式,具体来说就是过滤出所有的汉字。- 有的时候你想要保留字体文件中的英文、数字字符,可以改用
-e ['\w\d']我用的就是这种方法
- 有的时候你想要保留字体文件中的英文、数字字符,可以改用
-oN --no-filename是控制打印结果的开关,具体来说:-o只打印匹配的字符串,因为默认情况下会打印匹配的整行-N不打印匹配的行号--no-filename不打印匹配的文件名 这样最后的结果只有匹配到的汉字而不会有干扰字符。
sort|uniq, 常见的哥俩好,用于对汉字进行排序去重tr -d '\n', 去掉换行符,将所有汉字合并到一行
这个命令会提取出当前目录 下所有文件中使用的汉字字符,并排序、去重,最后生成一个合并好的汉字列表:
一万丈三上下不与丑专且世业东丝丢两严丧个中丰串临为主丽举久么义之乎乏乐乔乘九也习乡书买了争事二于亏云互五亚些亡交亦产享亮亲人什仅今介仍从仓仔他付代令以仪们件价任份仿伐优伙会伟传伤伪伯伴伸似但位住体何余佛作你佩佬佳使侄例供依侧便促俄俗保信修倍倒候借倦值假偏做停健偶偷催傲傻像僧儿充兆先光克免党入全八公六共关兴其具典养兼内册再冗写农冥冲决况准几出击分切刍刑划列则刚创初删判利别到制刷刺刻前剧剩割力办功加务劣动助努励劳势勇勉勿匀包化匮区医十千升午半华卑单卖南博占卡卢卧卫卯印危即却卸厅历压厌厘厚原厢去县参又及友双反发取受变叠口古句另只叫召叭可台史右叶号司叹吃各合吉吊同名后吐向吗君吞否吧含听启吵吸呆告员呢周味呼命咀和咧哀品哈哉响哥哨哪哭哲唤唯商啊啥喀喂善喇喜嗯嘛嘴噜器噩嚼囚四回因团困围固国图圆圈在地场址均坏坐坑坚坛坠坨垂垄型埋城域培基堂堆堵塔填境墙增士声处备复夏夕外多夜够大天太夫央失头夹夺奇奈奋奏契奔套女她好如妇妒妙妻姆始姐姑威娱婚媒嫁嫉嫌子孔字存孤孥学它守安完宗官定宜实审客室害宵家容宽宿密富察寥寸对寺寻导封射将小少尔尚尝尤就尸尺尼尽尾层居屎屏展履山岁岔峰崇崩巅川工左巧巨差己已巴市师希帖带帧帮常幅幕干平年并幸幻幽广床序库应底店废度座康建开异弃式弓引弟张弱弹强归当录形彦影彻彼往征径待很徒得微德心必忆忍志忘忙忧快念忽怀态怎怒怕怖怜思怠急性怪总恋恐恒恢恨息恰恶悉悚悠患悬悲情惊惜惬惯想愈愉意愚感愤愿慌慕慢慧憾懂懒戏成我或战截戴户房所手才打托执扭扯扰批找承技抄把抑抒抓投抖抗折抛报披抱抵抹抽担拉拍拒拖招拜拟拥择括拯拷拼拽拿持挂指按挑挖挡挪振挺挽捆捏损换据掀授掉掌排探接控推揉描提插握搜搞搬搭摆摇摧撕撞播操攀支收改攻放故效敏救教敢散数敲整文斗料斜斥斩断斯新方施旁旅族无既日旦旧早时明昏易星映春昨是显晚普景晰智暂暇暖暗暴更曼曾替最月有朋服望朝期木未末本术朱朴机杀杂权材村束条来松板极构林果枯架某染柔柜查标栏树栗校样核根格框案桌档桥梦梭梯棋森棵椅椎楚楼概槽模横次欢欣欲款歌止正此步死殊残段毁毅母每比毕毛毫毯民气気氧水永求汉池污汤沉沙没沸治沿泌法泣泥注洁津洪活流浏浑浪浮浴海浸涂消涉涌涎涣润涩淡淤深添清渐渡温渲渴游湿溃源滋滑滚满滥滴漂演漠漫潜潭澡激火灭灯灰灵炫炭炸点烂烈烟烦热然煤熟燃燕爱爵爹爽片版牙物特犯状犹狂狐狗独狱猫率玛玩环现珍班球理琐瑾甚甜生用田由电男画畅界留畜略番疑疗疲疼疾病症痊痕痛痴瘠瘾癣白百的皮益盖盘目直相省眈看真眠眼着睁睛睡督瞎知矫短石矿码研础硬确碍碎磨示社神票禁禅福离秀私秉秋种科秘积称移稀程稳稿究空穿突窃窍窗窥立竖站竟章童端笑笔符第笼等答签简算管箭箱篇篮类粗精糊糕糖糗糟系素索紧繁约级纪纯纱纳纷线练组细终经绑结绘给络绝统继绪续绳维绿编缘缸缺网罚罢罩罪置署美羡翻老考者而耍耐耳聊职联聘肃肉股肤肥肩肯育肺胆背胎胜胳胶胺能脆脉脊脑脚脱脸腐腕腰腹腻腾膀膊自臭至致舍舒舞般艰色艳艺节花苟苦英苹茄茫草荐荒荡药莫获菜萤萨落著葩蒋蓝蔑蔽薄藏虎虑虚虽蛋蜃蠢血行衔街衡衣补表衷袋被袭袱装裹褂西要覆见观规觅视览觉角解触言警计认讨让记讲许论设访诀证识诉词译试诛话诡该详语误说请诸读课谁调谈谐谜谢谨象豪豫贝负败账质贫贴贵费资赐赖赚赛赞赢赫走赴赶起超越趟趣足跑跟路践踏踩踪躁身躬躺车轨转轮轰轴轻载较辅辆辑输辗辙辛辞辨边达迁过迎运近还这进远违连迟迫述迷迹追退送适逃选透逐途通逛逝速造逻遇遍道遗遵避那邪邻郁郎部都酉配酬酷醉醒释里重野量金钉钟钦钩钮钱铃链锁错键镇长门闪闭问闲间闷闹闻闾阅阔队阳阴阵阻阿附际陆陌限院除险陪陷随隐隔障隧难雅集雨雪零需震露青静非靠面革鞠音韶页顶项顺须顾预领频题颜额风飞食餐饥饭馆馈馋首香马驰驶驼驾骂骇验骑骗骤骨高鬼魂魄魔鱼鲜鸟鸡鸦麻黄黑默鼓鼠鼻齐龄
说实话,第一次得到这个结果的时候我是很惊讶的——我用到的汉字居然才这么点,才1526 个?
接下来的事情就非常简单了,以我使用的静态博客生成工具 hugo 为例,只要在 deploy 的时候进入 public 目录查找出所有的汉字然后用 fonttools 对字体文件进行压缩即可。
下面是我写的脚本(修改自 hugo 官方的 deploy.sh)
#!/bin/sh
# If a command fails then the deploy stops
set -e
printf "\033[0;32mDeploying updates to GitHub...\033[0m\n"
# Build the project.
hugo # if using a theme, replace with `hugo -t <YOURTHEME>`
# Go To Public folder
cd public
# 原始字体名称
origin='yuyang.ttf'
# 压缩后的字体名称,注意需要和 font-face中定义的字体名一致
optimized='result.woff2'
echo "开始根据使用情况缩减字符..."
pyftsubset "fonts/$origin" --text=$(rg -e '[\w\d]' -oN --no-filename|sort|uniq|tr -d '\n') --no-hinting
echo "缩减完成,开始转换到woff2格式"
fonttools ttLib.woff2 compress -o "fonts/$optimized" "fonts/${origin/\./\.subset\.}"
echo "删除中间文件..."
rm "fonts/${origin/\./\.subset\.}"
echo "压缩完成,继续部署..."
# Add changes to git.
git add .
# Commit changes.
msg="rebuilding site $(date)"
if [ -n "$*" ]; then
msg="$*"
fi
git commit -m "$msg"
# Push source and build repos.
git push origin master
注意在上面这个脚本中,我使用了 fonttools ttLib.woff2 compress命令。
这个命令的作用是将生成的 ttf 转换为 woff2 格式,这进一步压缩了字体文件,最后生成的文件只有 162.8K, 压缩了将近一半。
总结
即便是将来写更多的文章,用到的汉字数量也不会有很大的增长,我想最后也不会超过200K。相比之下,普通的英文字体大小大约在20K~30K左右,这其实已经是一个完全可以接受的大小了。
另外就是整体部署的时间也并没有因此变得很长,增加字体相关操作大概耗时3秒左右,总体部署耗时14秒,没有增加什么时间成本。
最后的上线效果也令人满意,大陆直连情况下加载字体文件也平均只需要500ms左右(和github的cdn波动有关,快的时候300ms,慢的时候700ms)。
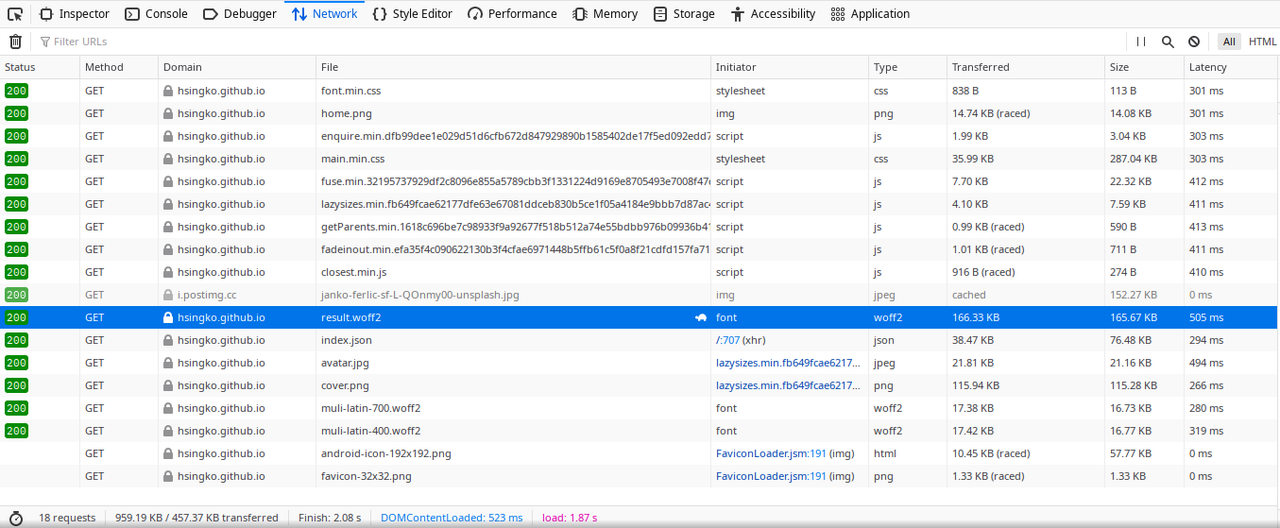
即便是用ctl F5强制刷新,加载的速度也非常快,基本不会感受到什么延迟,如果换用国内的CDN还能更快。综上,中文 webfont 完全可以称得上能用了。
为了把自己的博客弄得顺眼一点我花了一个晚上的时间折腾出了字体方案,又花了两个多小时写这篇博客,可算是把自己折腾得够惨。不过生命就在于折腾,在过程中我也学到了许多东西,所以以后还要继续折腾:P