一个简易的微信公众号文章爬虫、备份的实现
2023-06-13
尽管我对微信深恶痛绝,但不得不承认的是公众号上面确实有很多值得一看的内容。然而问题是上面的文章对于搜索引擎是不可见的(除了搜狗),并且 PC 上也没有相应的入口来访问相应的文章列表。又考虑到平台严格的内容审查,常常会遇到刚刚还能看的文章,下一刻就没法看了的情况。
该如何获取并永久地保存这些文章?
对于这种需求,已经有很多免费或付费的实现,其原理要么是基于手机流量抓包,要么是利用微信平台自身的引用机制。但无论如何,上手都存在相对较高的成本。
但在一些情况下,公众号爬虫其实并不需要做得那么复杂,条件是:
- 只要知道文章的链接,不需要登录也能查看文章全文
- 作者常常会在文章中给出其它相关文章的链接;将作者的所有文章想像成一个个节点,彼此之间互相联通;假如这是一个连通图,那么自然更好,而即便这个图不连通,通过一个好的入口也能获取到大部分文章的连接
以下是我的实现。
爬虫部分
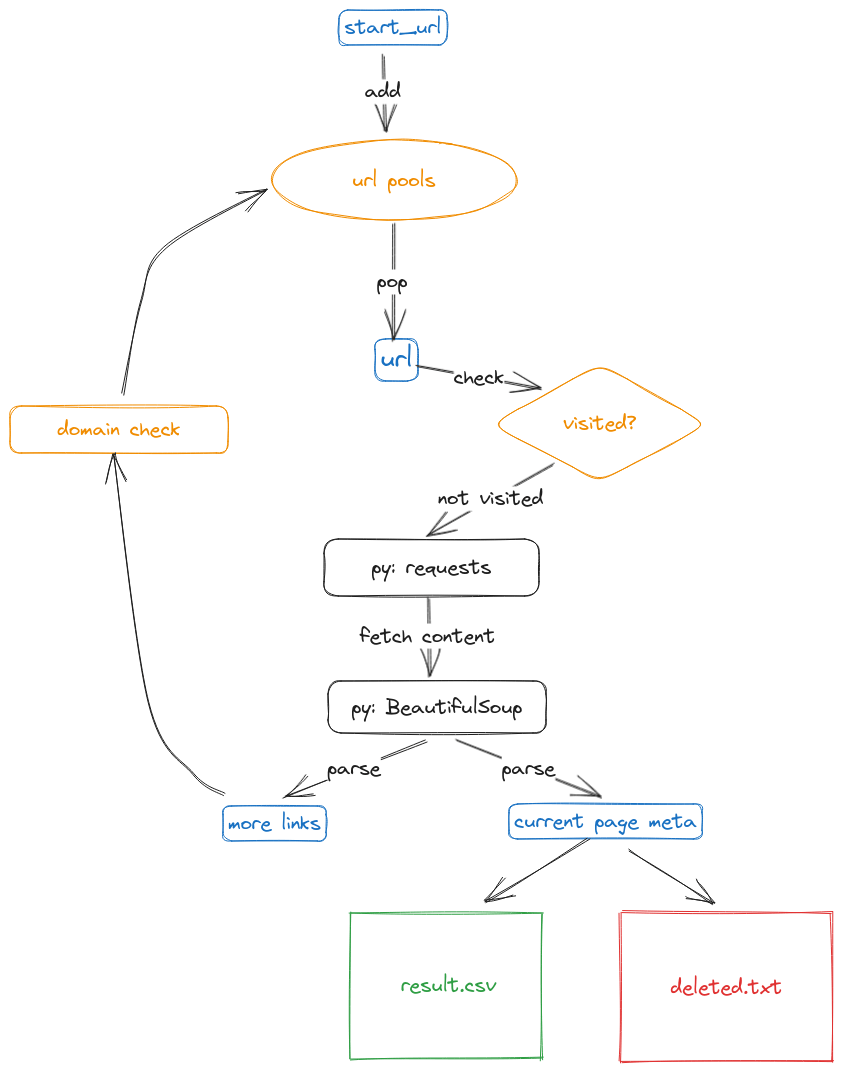
爬虫的本质是:
- 维护一个 url 列表,不断地从这个列表中取出地址,访问对应页面,解析出更多的 url 加入到这个列表中
同时你也会注意到一些细节,比如:
- 我们应该记录下已经访问过的 url ,下次取到这个 url 就直接略过,否则这个爬虫会陷入死循环
- 我们也应该过滤一些 url ,比如对跨网站的链接我们并不感兴趣
- 也要考虑服务器防火墙对频繁访问的检测,可以使用随机间隔的方法来绕过
思考出上图所示的结构,我们可以更进一步地考虑如何用 python 实现的细节:
- 数据结构
- 通过
pool=[start_url]初始化 url 列表 - 通过
visited=set()来记录访问过的 url
- 通过
- 利用 requests 和 BeautifulSoup 来访问和解析 url ;通过 urllib 来判定该 url 是否跨站
最后,我们来观察一下公众号文章 url 的模式,它长这样:
https://mp.weixin.qq.com/s?__biz=....&idx=1&mid=...&sn=...&...
关键字段是 __biz , mid 以及 sn 于是我们可以用 (biz, mid, sn) 这个三元组作为文章的唯一 id ,并记录到 visited 中。这里我们不直接用 url 本身来记录访问历史,因为微信可能会在请求参数后面添加一些 payload 。
代码非常简单:
from bs4 import BeautifulSoup
import requests
from urllib.parse import urlparse, parse_qs
import time
import random
import csv
def is_in_domain(url, domain):
parsed_url = urlparse(url)
parsed_domain = parsed_url.netloc
return parsed_domain == domain
def get_query_parameter(url):
parsed_url = urlparse(url)
paras = parse_qs(parsed_url.query)
return paras
def get_links(soup):
links = soup.find('div', {'id': 'page-content'}).find_all('a')
result = []
for link in links:
href = link['href']
result.append(href)
return result
start_url = 'https://mp.weixin.qq.com/s?...' # 自定义初始 url
domain = 'mp.weixin.qq.com'
pool = [start_url]
visited = set()
csv_file = "result.csv"
deleted_file = "deleted.txt"
data = []
deleted = set()
while pool:
curr = pool.pop()
paras = get_query_parameter(curr)
biz = paras['__biz'][0]
mid = paras['mid'][0]
sn = paras['sn'][0]
if (biz, mid, sn) in visited:
continue
visited.add((biz, mid, sn))
resp = requests.get(curr)
soup = BeautifulSoup(resp.content, 'html.parser')
## 检验文章是否被删除
if not soup.find('meta', property="og:title"):
deleted.add(curr)
continue
title = soup.find('meta', property="og:title")['content']
desc = soup.find('meta', property="og:description")['content']
image = soup.find('meta', property="og:image")['content']
data.append((title, desc, image, curr))
print(f"title={title}, url={curr}")
links = get_links(soup)
for link in links:
if not is_in_domain(link, domain):
continue
pool.append(link)
time.sleep(random.uniform(3, 7)) # 随机访问延时以对抗屏蔽
with open(csv_file, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(data)
with open(deleted_file, 'w', newline='') as file:
file.writelines('\n'.join(deleted))
程序执行结束后会在当前目录下生成 result.csv 和 deleted.txt 。前者包含文章标题、头图、链接,后者是已经被微信屏蔽的文章地址列表。
网页存档部分
上一步骤只是获取了某个公众号上的大部分文章的链接(孤立的文章需要手动添加),要获取对应的内容还需要花一点功夫。
可以使用 single-file-cli1 来将相应的页面保存到一个 html 文件中。
使用非常简单:
single-file \
--back-end=webdriver-chromium \
--load-deferred-images-dispatch-scroll-event \
--filename-template "{page-title}.html" \
--urls-file urls \
--output-directory out \
--max-parallel-workers 1 \
--browser-script remove-recommend.js
参数解释:
back-end这里使用 chromium 的 driver ,根据我自己的体验,其它的 driver 不怎么好用,当然你得先装 chromium/chrome 浏览器load-deferred-images-dispatch-scroll-event。微信文章中的图片是懒加载的,开启这个选项来模拟页面滚动filename-template这里使用了文章标题作为文件名urls-file一个 url 列表文件, sing-file 会自动遍历其中所有的链接。上一步我们得到了文章详细信息的 metadata ,可以通过awk -F ',' '{print $4}' result.csv > urls来提取 url 列表max-parallel-workers 1避免被封 IP ,只开启一个线程browser-script remove-recommend.js在保存页面之前,可以执行自定义脚本。我用来删除底部的文章推荐,你也可以不用,我删掉是因为微信推荐的文章都太辣眼睛了
删除底部微信推荐文章的 remove-recommend.js 的代码2:
dispatchEvent(new CustomEvent("single-file-user-script-init"));
addEventListener("single-file-on-before-capture-request", () => {
var eles = document.querySelectorAll(".rich_media_area_extra");
eles.forEach(item => {
item.remove();
window.scrollTo(0, 0);
});
});