在 emacs 中实现拼音首字母搜索的新思路
2024-02-03
目前根据拼音搜索中文的思路大致是暴力生成汉字匹配字典,然后拼接成正则表达式,比如 ace-pinyin 。在 consult 等搜索框架中也可以用 advice 的形式注入处理后的正则表达式实现拼音搜索,比如这些帖子。
我一直在想有没有反过来的方法?比如先让汉字转换成拼音,然后再直接搜索?不过那样的问题是需要对数据进行预处理,先不说性能方面比起复杂的正则有没有优势,搜索时能正常显示匹配字符的高亮吗?比如在用 consult 的时候,在不知用什么方法在 candidates 里面插入了不可见的拼音序列,匹配高亮该怎么做呢?
今天我突然想到一个方法:为什么不将中文先替换成拼音首字母,然后再用 text-property 让它看上去是一串中文呢,于是有了下面的 demo :
;;原始字符串:你好,世界
(setq my-string "nh,sj")
(add-text-properties 0 1 '(display "你") my-string)
(add-text-properties 1 2 '(display "好") my-string)
(add-text-properties 2 3 '(display ",") my-string)
(add-text-properties 3 4 '(display "世") my-string)
(add-text-properties 4 5 '(display "界") my-string)
(insert my-string) ;; 你好,世界
(consult--read (list my-string "test1" "测试2"))
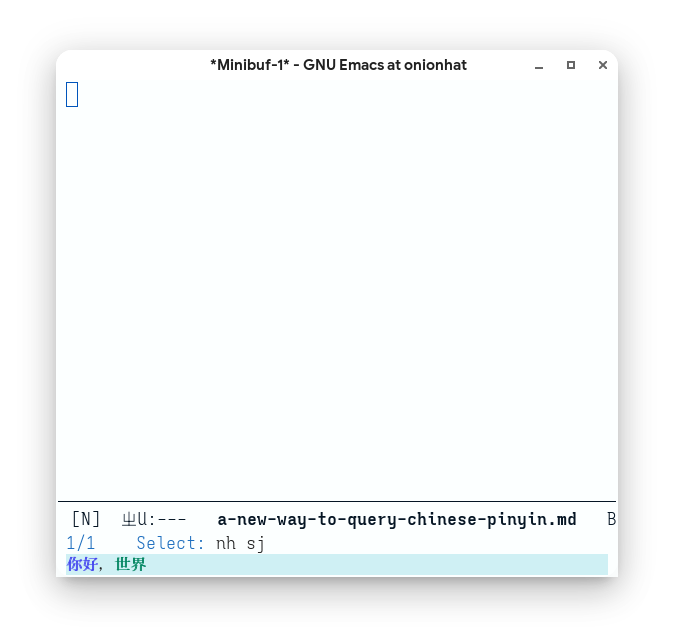
可以看到 consult 里面的匹配高亮是正常的,这证明了这种思路是完全可行的,甚至如果将这个处理后的字符串插入 buffer 中,用 isearch-forword 、avy 等也是能够搜索到的。理论上我们完全可以将一个 buffer 中的所有汉字都进行这种处理,比拼接正则,这种方法的优点是完全无需对搜索函数进行处理。尽管一个字一个字处理 text-property 似乎显得非常麻烦,但我想用来搜索相对固定的中文文件名应该够用了。
成果
于是我完成了这个包:the-magical-str.el ,证明这种思路来搜索文件是完全可行的。等我继续使用一段时间后再看看实际效果如何。